고객 재구매 예측 실습
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import koreanize_matplotlib
# 데이터 로드
df = pd.read_csv("customer_repurchase.csv")
df.info()
# 첫 구매 금액과 재구매율의 관계
plt.figure(figsize=(10, 6))
sns.boxplot(x="Repurchased", y="First Purchase Amount ($)", data=df)
plt.title("첫 구매 금액과 재구매율의 관계")
plt.xlabel("Repurchased (0=No, 1=Yes)")
plt.ylabel("First Purchase Amount ($)")
plt.show()
# 첫 구매 후 경과일과 재구매율의 관계
plt.figure(figsize=(10, 6))
sns.boxplot(x="Repurchased", y="Days Since First Purchase", data=df)
plt.title("첫 구매 후 경과일과 재구매율의 관계")
plt.xlabel("Repurchased (0=No, 1=Yes)")
plt.ylabel("Days Since First Purchase")
plt.show()
# VIP / 일반 고객별 재구매율 비교
plt.figure(figsize=(8, 5))
sns.barplot(x="Loyalty Tier", y="Repurchased", data=df)
plt.title("VIP / 일반 고객별 재구매율 비교")
plt.xlabel("Loyalty Tier (0=일반, 1=VIP)")
plt.ylabel("Repurchased")
plt.show()
# 할인 쿠폰 사용 여부와 재구매율 비교
plt.figure(figsize=(8, 5))
sns.barplot(x="Used Discount", y="Repurchased", data=df)
plt.title("할인 쿠폰 사용 여부에 따른 재구매율 비교")
plt.xlabel("Discount Offered (0=No, 1=Yes)")
plt.ylabel("Repurchased")
plt.show()
# 데이터셋 분리
X = df.drop(columns=["Repurchased"])
y = df["Repurchased"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 로지스틱 회귀 모델 학습
model = LogisticRegression()
model.fit(X_train, y_train)
# 예측 및 평가
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"모델 정확도: {accuracy:.2f}")
print("분류 보고서:\n", classification_report(y_test, y_pred))
# 혼동 행렬 시각화
plt.figure(figsize=(6, 4))
sns.heatmap(confusion_matrix(y_test, y_pred), annot=True, fmt='d', cmap='Blues')
plt.title("혼동 행렬")
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.show()다중 분류
세 개 이상의 클래스를 분류하는 문제이다.
ex) 손글씨 숫자 인식 (MNIST 데이터셋) -> 0~9까지의 10개 숫자 분류, 상품 추천 시스템 -> 여러 구매 성향별 고객 분류
소프트맥스 함수
이진 분류에서는 시그모이드 함수를 사용하지만 다중 분류에서는 소프트맥스 함수를 사용한다.
각 클래스에 대한 확률 값을 출력하며, 확률 합은 항상 1이 된다.
가장 확률이 높은 클래스를 최종 예측값으로 선택한다.
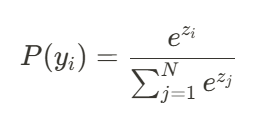
예제
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.linear_model import LogisticRegression
# 1. 가상의 마케팅 데이터 생성
data = {
'age': [22, 45, 25, 47, 35, 50, 29, 41, 60, 33, 39, 28, 49, 53, 67],
'spending_score': [80, 55, 90, 40, 70, 35, 85, 50, 20, 75, 65, 58, 15, 35, 20],
'ad_click_rate': [0.9, 0.3, 0.8, 0.2, 0.7, 0.1, 0.85, 0.4, 0.05, 0.75, 0.6, 0.88, 0.15, 0.62, 0.2],
'email_open_rate': [0.95, 0.4, 0.9, 0.3, 0.75, 0.2, 0.89, 0.5, 0.1, 0.78, 0.65, 0.91, 0.37, 0.26, 0.35],
'engagement_level': ['Good', 'Normal', 'Good', 'Angry', 'Good', 'Angry', 'Good', 'Normal', 'Angry',
'Good', 'Normal', 'Good', 'Normal', 'Good', 'Normal']
}
df = pd.DataFrame(data)
# 2. 독립변수(X)와 종속변수(y) 설정
X = df[['age', 'spending_score', 'ad_click_rate', 'email_open_rate']]
y = df['engagement_level']
# 3. 라벨 인코딩 (문자 → 숫자 변환)
label_encoder = LabelEncoder()
y_encoded = label_encoder.fit_transform(y)
# 4. 데이터 정규화
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 5. 훈련/테스트 데이터 분할 (7:3 비율)
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y_encoded, test_size=0.3, random_state=42, stratify=y_encoded)
# 6. 로지스틱 회귀 모델 훈련 (다중 분류)
model = LogisticRegression(multi_class='multinomial', solver='lbfgs', max_iter=200)
model.fit(X_train, y_train)
# 7. 테스트 데이터 예측
y_pred = model.predict(X_test)
# 8. 예측 결과 출력
print("테스트 데이터 예측 결과:")
for i, pred in enumerate(y_pred):
print(f"테스트 데이터 {i+1}: 예측된 참여 수준 - {label_encoder.inverse_transform([pred])[0]}")
결정 트리
트리 구조를 사용하여 데이터를 분류하거나 회귀하는 지도 학습 알고리즘이다.
각 노드는 특정 특징을 기준으로 데이터를 나누는 역할을 하며, 최종 예측값을 도출한다.

결정 트리를 사용하면 논리적 규칙 기반으로 분류 가능하여 해석이 쉽고, 결측치 및 이상치 처리, 스케일링 등 전처리가 거의 필요 없으며, 범주형 및 연속형 데이터 모두 처리가 가능하다.
단 트리가 너무 깊어지면 과적합 위험이 있으며, 데이터가 조금만 바뀌어도 트리 구조가 크게 달라질 수 있다. 또한 일부 데이터에서는 균형이 맞지 않는 트리가 생성될 수 있다.
가지치기
결정 트리가 과적합되는 것을 방지하기 위해 불필요한 가지를 제거하는 과정이다.
너무 많은 노드를 사용하면 데이터에 너무 맞춰진 복잡한 모델이 될 수 있다.
사전에 미리 트리의 최대 깊이, 최소 샘플 수를 제한하여 과적합을 방지할 수 있다.
트리를 최대한 성장시킨 후 성능이 저하되지 않은 범위에서 불필요한 노드를 제거하여 모델을 단순화할 수 있다.
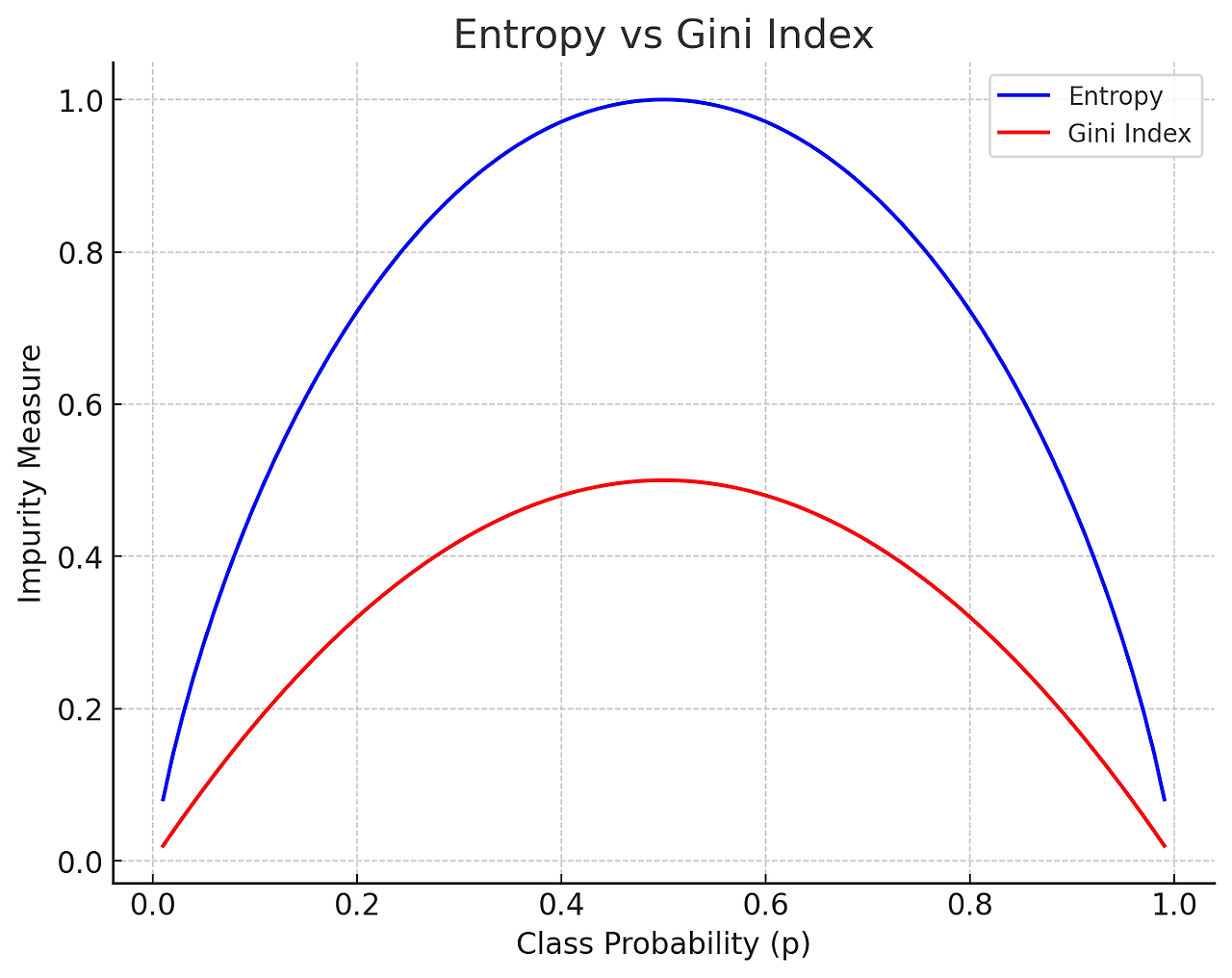
엔트로피와 지니 계수
엔트로피와 지니 계수 모두 데이터의 불순도를 낮추는 역할을 하지만 지니 계수는 계산이 더 빠르고, 엔트로피는 좀 더 정밀한 분류를 유도한다. 실제 프로젝트에서는 두 방법을 비교하여 더 좋은 결과를 내는 방식을 선택한다.
엔트로피
데이터의 불확실성을 측정하는 값이다.
값이 낮을수록 불확실성이 적으며, 하나의 클래스로 치우쳐진 데이터이다.
엔트로피가 가장 크게 감소하는 기준으로 데이터를 분할한다.
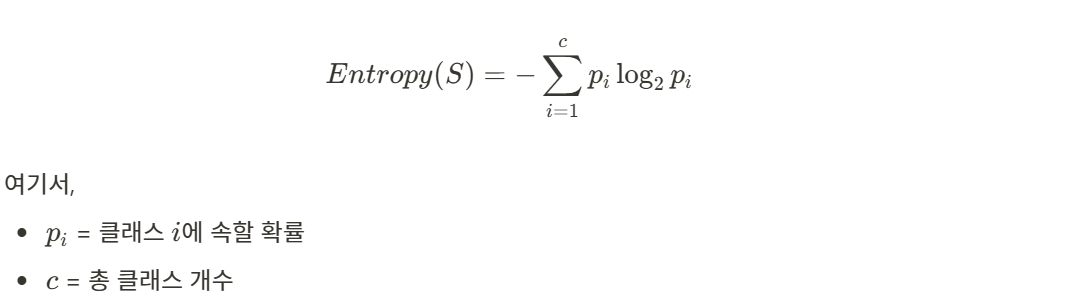
지니 계수
데이터의 불순도를 측정하는 값이다.
값이 낮을수록 데이터가 특정 클래스에 속할 확률이 높으며, 해당 특징을 기준으로 데이터를 나누는 것이 효과적임
예제
import numpy as np
def calculate_gini(labels):
"""
지니 계수(Gini Index)를 계산하는 함수
- 공식: Gini = 1 - sum(p_i^2)
- 값이 낮을수록 한쪽 클래스에 집중된 데이터
labels: 리스트 형태의 클래스 라벨 (예: [0, 1, 1, 0, ...])
반환값: 지니 계수 (0~1 사이 값)
"""
unique_classes, counts = np.unique(labels, return_counts=True) # 각 클래스의 개수 계산
probabilities = counts / len(labels) # 각 클래스의 확률 계산
gini = 1 - np.sum(probabilities**2) # 지니 계수 계산
return gini
def calculate_entropy(labels):
"""
엔트로피(Entropy)를 계산하는 함수
- 공식: Entropy = -sum(p_i * log2(p_i))
- 값이 낮을수록 한쪽 클래스에 집중된 데이터
labels: 리스트 형태의 클래스 라벨 (예: [0, 1, 1, 0, ...])
반환값: 엔트로피 값 (0~1 사이 값, 균등할수록 1에 가까움)
"""
unique_classes, counts = np.unique(labels, return_counts=True) # 각 클래스의 개수 계산
probabilities = counts / len(labels) # 각 클래스의 확률 계산
entropy = -np.sum(probabilities * np.log2(probabilities)) # 엔트로피 계산
return entropy
# 예제 데이터 (0: "구매 안 함", 1: "구매")
labels = [0, 0, 0, 0, 1, 1, 1, 1, 1, 1] # 0이 4개, 1이 6개 (비율: 0.4 vs 0.6)
# 지니 계수 및 엔트로피 계산
gini_value = calculate_gini(labels)
entropy_value = calculate_entropy(labels)
# 결과 출력
print(f"지니 계수: {gini_value:.4f}") # 0.4800 (순도가 낮음)
print(f"엔트로피: {entropy_value:.4f}") # 0.9709 (데이터가 혼합됨)결정트리 분류 예측 예제
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.metrics import accuracy_score
# 1. 가상의 고객 데이터 생성 (하드코딩된 값 사용)
data = {
"Frequency": [3, 10, 5, 8, 1, 12, 4, 7, 6, 2],
"Avg_Purchase_Amount": [30, 120, 80, 150, 10, 200, 50, 100, 90, 20],
"Email_Response": [1, 0, 1, 1, 0, 1, 0, 1, 1, 0],
"Social_Media_Activity": [2, 8, 4, 7, 0, 10, 3, 6, 5, 1],
"Purchase": [0, 1, 1, 0, 1, 0, 0, 1, 1, 1] # 타겟 변수 (1: 구매, 0: 구매 안 함)
}
# 데이터프레임 생성
df = pd.DataFrame(data)
# 2. 입력(X)과 타겟(y) 분리
X = df.drop(columns=["Purchase"]) # 독립변수
y = df["Purchase"] # 종속변수 (목표 예측값)
# 3. 데이터 분할 (훈련 데이터 80%, 테스트 데이터 20%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 4. 의사결정트리 모델 학습
dt_model = DecisionTreeClassifier(max_depth=3, random_state=42)
dt_model.fit(X_train, y_train)
# 5. 모델 예측
y_pred = dt_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
# 6. 결정 트리 시각화
fig, ax = plt.subplots(figsize=(12, 6))
plot_tree(dt_model, feature_names=X.columns, class_names=["No Purchase", "Purchase"], filled=True, ax=ax)
plt.title(f"Decision Tree for Growth Marketing Campaign (Accuracy: {accuracy:.2f})")
plt.show()
# 7. 고객 데이터 입력 후 구매 예측 함수 (Feature Name 문제 해결)
def predict_purchase(Frequency, Avg_Purchase_Amount, Email_Response, Social_Media_Activity):
"""
입력한 고객 데이터를 기반으로 구매 여부를 예측하는 함수
"""
# 입력 데이터를 DataFrame 형태로 변환하여 Feature Names 유지
input_data = pd.DataFrame([[Frequency, Avg_Purchase_Amount, Email_Response, Social_Media_Activity]],
columns=X.columns)
prediction = dt_model.predict(input_data)
return "구매할 가능성이 높음" if prediction[0] == 1 else "구매하지 않을 가능성이 높음"
# 8. 예제 입력 데이터 (사용자가 예측하고 싶은 값)
example_input = {
"Frequency": 14, # 웹사이트 방문 횟수
"Avg_Purchase_Amount": 100, # 평균 구매 금액
"Email_Response": 1, # 이메일 캠페인 반응 여부 (1: 반응, 0: 반응 없음)
"Social_Media_Activity": 6 # 소셜 미디어 활동 횟수
}
# 9. 예측 실행
prediction_result = predict_purchase(**example_input)
print(f"예측 결과: {prediction_result}")
예측 결과: 구매할 가능성이 높음
결정트리 회귀 예측 예제
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor, plot_tree
from sklearn.metrics import mean_absolute_error, r2_score
# 1. CSV 파일 로드
df = pd.read_csv("서울시 상권분석 데이터.csv")
# 2. "성수동카페거리" 데이터 필터링
df = df[df["상권_코드_명"] == "성수동카페거리"]
# 3. 필요없는 컬럼 제거
drop_columns = ["기준_년분기_코드", "상권_구분_코드", "상권_구분_코드_명", "상권_코드", "상권_코드_명",
"서비스_업종_코드", "서비스_업종_코드_명"] # 분석에 필요 없는 컬럼 제거
df = df.drop(columns=drop_columns)
# 4. 결측값 제거
df = df.dropna()
# 5. 입력(X)과 타겟(y) 분리
X = df.drop(columns=["당월_매출_건수"]) # 입력 변수 (매출 건수를 예측해야 하므로 제외)
y = df["당월_매출_건수"] # 타겟 변수 (예측 대상)
# 6. 데이터 분할 (훈련 80%, 테스트 20%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 7. 결정트리 회귀 모델 학습
dt_model = DecisionTreeRegressor(max_depth=5, random_state=42)
dt_model.fit(X_train, y_train)
# 8. 모델 예측 및 평가
y_pred = dt_model.predict(X_test)
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Mean Absolute Error (MAE): {mae:.2f}")
print(f"R² Score: {r2:.2f}")
# 9. 결정 트리 시각화
fig, ax = plt.subplots(figsize=(15, 8))
plot_tree(dt_model, feature_names=X.columns, filled=True, ax=ax, fontsize=8)
plt.title(f"Decision Tree for Monthly Sales Count Prediction (R² Score: {r2:.2f})")
plt.show()
# 10. 예측 함수
def predict_sales_count(data_input):
input_data = pd.DataFrame([data_input], columns=X.columns)
prediction = dt_model.predict(input_data)
return f"예상 당월 매출 건수: {prediction[0]:,.0f} 건"
# 예측 예시
sample_input = X.iloc[0].values # 첫 번째 샘플 데이터로 예측
print(predict_sales_count(sample_input))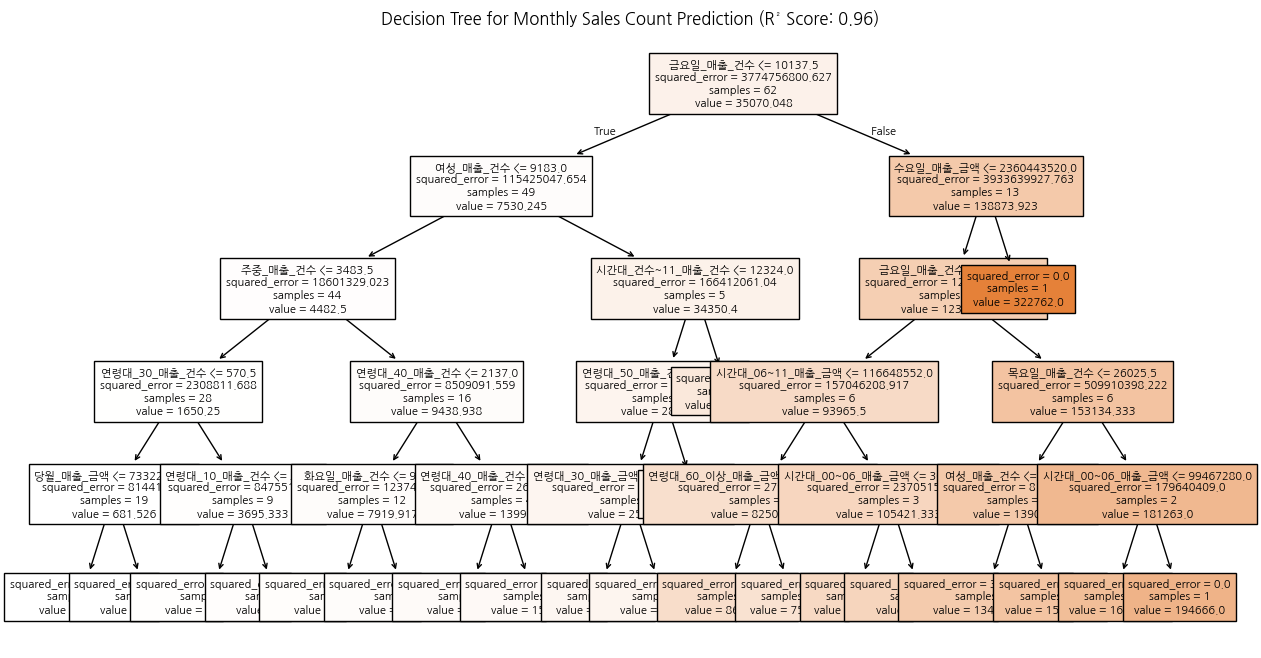
Mean Absolute Error (MAE): 4195.97
R² Score: 0.96
예상 당월 매출 건수: 1,032 건
랜덤 포레스트
여러 개의 결정 트리를 조합하여 예측 성능을 향상시키는 앙상블 학습 기법이다. 단일 결정 트리의 한계를 극복하고 과적합을 줄이며, 예측 성능을 개선하는 데 효과적이다.
배깅 방식을 기반으로 여러 개의 결정 트리를 학습하고, 각 트리의 예측을 분류 또는 회귀하여 최종 예측값을 도출한다.

랜덤 포레스트 분류 예제
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# 데이터 로드
df = pd.read_csv("ad_click_prediction.csv")
# 독립 변수(X)와 종속 변수(y) 설정
X = df.drop(columns=["Clicked Ad"])
y = df["Clicked Ad"]
# 학습/테스트 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 랜덤 포레스트 모델 학습
rf_model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=42)
rf_model.fit(X_train, y_train)
# 예측 및 평가
y_pred = rf_model.predict(X_test)
print("모델 정확도:", accuracy_score(y_test, y_pred))
print("분류 보고서:\n", classification_report(y_test, y_pred))
# 혼동 행렬 시각화
plt.figure(figsize=(6, 4))
sns.heatmap(confusion_matrix(y_test, y_pred), annot=True, fmt='d', cmap='Blues')
plt.title("혼동 행렬 (Confusion Matrix)")
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.show()
# 특징 중요도 시각화
feature_importances = rf_model.feature_importances_
feature_names = X.columns
plt.figure(figsize=(10,6))
sns.barplot(x=feature_importances, y=feature_names, color="royalblue")
plt.xlabel("Feature Importance")
plt.ylabel("Features")
plt.title("랜덤 포레스트 - 광고 클릭 예측 특징 중요도")
plt.show()
랜덤 포레스트 회귀 예제
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error, r2_score
# 1. CSV 파일 로드
df = pd.read_csv("서울시 상권분석 데이터.csv")
# 2. "발달상권" 데이터 필터링
grouped_df = df[df["상권_구분_코드_명"] == "발달상권"]
# 3. 필요없는 컬럼 제거
drop_columns = ["기준_년분기_코드", "상권_구분_코드", "상권_구분_코드_명", "상권_코드", "상권_코드_명",
"서비스_업종_코드", "서비스_업종_코드_명"] # 분석에 불필요한 컬럼 제거
grouped_df = grouped_df.drop(columns=drop_columns)
# 4. 결측값 제거
grouped_df = grouped_df.dropna()
# 5. 입력(X)과 타겟(y) 분리
X = grouped_df.drop(columns=["당월_매출_금액"]) # 입력 변수
y = grouped_df["당월_매출_금액"] # 타겟 변수 (예측 대상)
# 6. 데이터 분할 (훈련 80%, 테스트 20%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 7. 랜덤포레스트 회귀 모델 학습
rf_model = RandomForestRegressor(n_estimators=100, max_depth=5, random_state=42)
rf_model.fit(X_train, y_train)
# 8. 모델 예측 및 평가
y_pred = rf_model.predict(X_test)
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Mean Absolute Error (MAE): {mae:.2f}")
print(f"R² Score: {r2:.2f}")
# 9. 변수 중요도 시각화
feature_importances = rf_model.feature_importances_
sorted_idx = np.argsort(feature_importances)[::-1]
plt.figure(figsize=(10, 6))
plt.bar(range(X.shape[1]), feature_importances[sorted_idx], align="center")
plt.xticks(range(X.shape[1]), X.columns[sorted_idx], rotation=90)
plt.xlabel("Feature")
plt.ylabel("Importance")
plt.title("Feature Importance in Random Forest Model")
plt.show()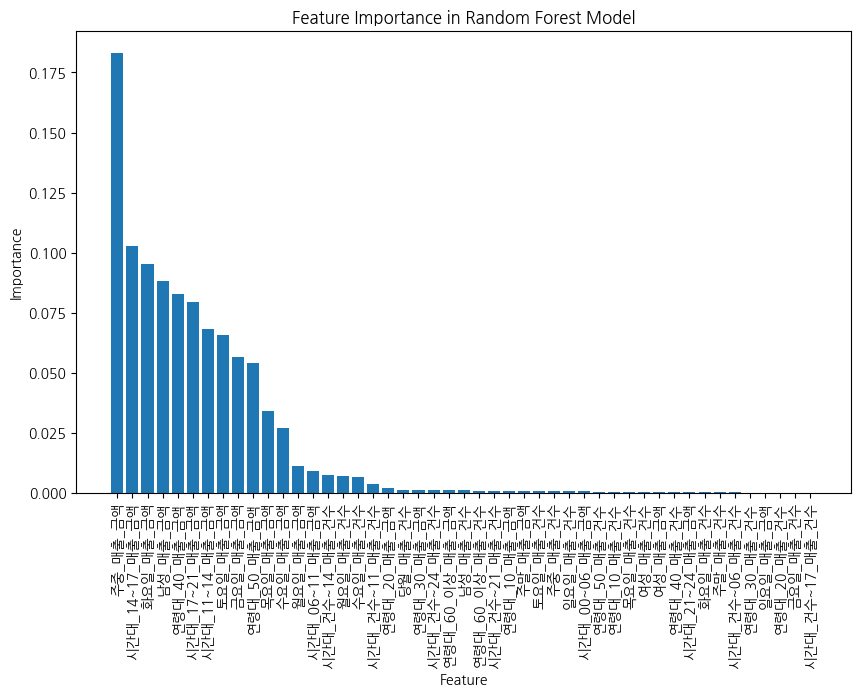
Mean Absolute Error (MAE): 387057364.34
R² Score: 0.99
# 입력(X)과 타겟(y) 분리
X = grouped_df[[
"주중_매출_금액",
"시간대_14~17_매출_금액",
"화요일_매출_금액",
"남성_매출_금액",
"연령대_40_매출_금액",
"시간대_17~21_매출_금액",
"시간대_11~14_매출_금액",
"토요일_매출_금액",
"금요일_매출_금액"
]] # 입력 변수
y = grouped_df["당월_매출_금액"] # 타겟 변수 (예측 대상)
# 데이터 분할 (훈련 80%, 테스트 20%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 랜덤포레스트 회귀 모델 학습
rf_model = RandomForestRegressor(n_estimators=100, max_depth=5, random_state=42)
rf_model.fit(X_train, y_train)
# 모델 예측 및 평가
y_pred = rf_model.predict(X_test)
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Mean Absolute Error (MAE): {mae:.2f}")
print(f"R² Score: {r2:.2f}")
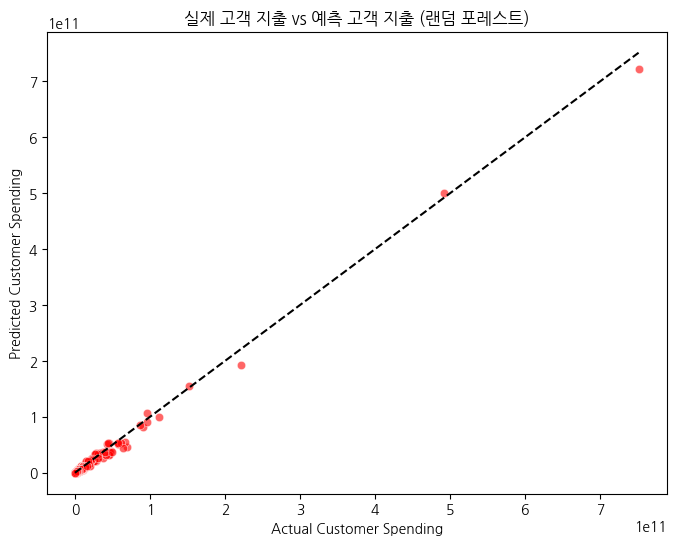
# 실제값 vs 예측값 시각화
plt.figure(figsize=(8,6))
sns.scatterplot(x=y_test, y=y_pred, alpha=0.6, color="red")
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], linestyle="--", color="black")
plt.xlabel("Actual Customer Spending")
plt.ylabel("Predicted Customer Spending")
plt.title("실제 고객 지출 vs 예측 고객 지출 (랜덤 포레스트)")
plt.show()
# 예측 함수
def predict_sales_count(data_input):
input_data = pd.DataFrame([data_input], columns=X.columns)
prediction = rf_model.predict(input_data)
return f"예상 당월 매출 금액: {prediction[0]:,.0f} 원"
# 예측 예시
sample_input = X.iloc[0].values # 첫 번째 샘플 데이터로 예측
print(predict_sales_count(sample_input))
예상 당월 매출 금액: 250,537,662 원
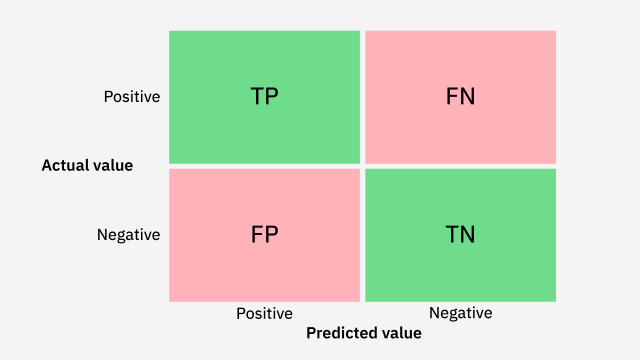
혼동 행렬
분류 모델의 예측 결과를 평가하는 데 사용되는 표이다.
'회고' 카테고리의 다른 글
| [멋쟁이사자처럼 그로스마케팅 부트캠프] 27일차 회고 (0) | 2025.03.13 |
|---|---|
| [멋쟁이사자처럼 그로스마케팅 부트캠프] 26일차 회고 (1) | 2025.03.12 |
| [멋쟁이사자처럼 그로스마케팅 부트캠프] 24일차 회고 (1) | 2025.03.10 |
| [멋쟁이사자처럼 그로스마케팅 부트캠프] 23일차 회고 (3) | 2025.03.07 |
| [멋쟁이사자처럼 그로스마케팅 부트캠프] 22일차 회고 (4) | 2025.03.06 |